
According to Gartner, cloud technology will become an essential business necessity by 2028, transforming from a mere operational tool into a strategic enabler for organizations across industries. As companies increasingly rely on cloud infrastructure to drive agility, innovation, and resilience, the shift will redefine competitive landscapes and streamline decision-making. By embracing the cloud as a foundational element, businesses can better position themselves to meet evolving demands and capitalize on digital growth opportunities in the coming years.
Moving from on-premises to cloud infrastructure is a complex process that requires careful planning and execution. It involves a significant shift in how organizations manage their IT infrastructure, and it can be challenging to navigate without proper guidance.
In this article, we will explore the key considerations and best practices for planning infrastructure while moving from rigid on-premises systems to the cloud. We will examine the benefits and challenges of migrating to the cloud and the crucial steps in a successful transition. By the end of this article, you will better understand how to plan and execute a successful migration to the cloud.
Business Challenge
Nearly two-thirds of our customers are encountering significant difficulties with the complexity of their on-premises systems, prompting a shift towards a more efficient cloud-based infrastructure. The company’s transformation was crucial to improving system management, deployment, maintenance, and scalability. These enhancements were expected to optimize resource utilization and overall performance.
Moreover, most companies strive to reduce the costs of running their old systems. These expenses were not only financial but also encompassed compliance and security management, both vital in some regulatory environments. Transitioning to cloud solutions promised enhanced flexibility and scalability, allowing the company to swiftly adjust to changing business needs and efficiently scale resources as required.
Let’s consider an example from one of our clients: A multinational healthcare company operates globally in the field of diagnostics through an innovative platform. It offers a comprehensive diagnostics solution that can be customized to meet the specific needs of any hospital, providing doctors with confidence in the treatment processes of their patients.
Specific Business Challenges
- System Complexity and Maintenance: The on-premises systems were complex and required extensive manual intervention for updates and maintenance, leading to high operational costs on each installation on the customer side, planned downtimes, and overtime working hours during the nights.
- High Costs of Legacy Systems: The financial burden of maintaining aging hardware, including network firewalls, servers, and data storage systems, was significant. Our clients spend approximately $2.4 million annually on support and licenses alone.
- Compliance and Security Management: Adhering to the latest industry regulations requires constant updates and patches, which is time-consuming and error-prone. This compliance process can expose the company to security risks, compliance issues, and unplanned downtimes.
- Due to fixed capacity constraints, the company struggled to efficiently scale its IT operations during peak diagnostic periods, impacting overall productivity and revenue.
Scalability Limitations (technical)
The company mainly used Java applications and Oracle databases, which presented significant challenges for scaling both horizontally and vertically. This lack of flexibility greatly hampered the company’s ability to expand its diagnostics capacity during peak infection seasons, resulting in decreased performance and delayed responsiveness to hospitals’ requests.
The reliance on Java applications and Oracle databases posed substantial obstacles to efficient scaling,both horizontally and vertically. The rigid infrastructure constrained the company’s ability to efficiently expand its diagnostics capacity during peak infection periods, leading to performance bottlenecks and delayed responsiveness to hospitals’ needs. The limitations of the bare-metal environment hindered dynamic scaling, making it increasingly challenging to adapt to fluctuating demand and maintain service levels. As a result, there was a clear need for a more flexible and scalable solution.
Operational Overhead
The existing infrastructure was comprised of more than 100+ bare metal servers in the single corporate data center, plus 50+ bare metal servers located at their clients’ sites. This setup supported more than 50 Java applications, including software for diagnosis of various diseases, ERP and CRM systems, data integration, and analytics applications, along with a set of public web servers. Maintaining this infrastructure required significant resources and effort. Routine operations were complicated by the rigid architecture, causing them to be time-consuming and error-prone. This operational inefficiency strained IT operations and diverted essential resources from other important initiatives.
Inflexibility and Agility Concerns
The current system’s rigid configuration limited the organization’s ability to quickly respond to market trends and take advantage of new opportunities. This lack of agility puts the company at a disadvantage in a competitive business environment, highlighting the need for a more responsive and efficient IT infrastructure.
Architectural Challenges
The software architecture lacked modern approaches, especially in data storage and processing. The systems were not designed for automatic scaling and did not incorporate the publisher-subscriber pattern for asynchronous data handling. These shortcomings affected the efficiency and scalability of IT infrastructure and limited the organization’s ability to fully utilize infrastructure capacity and capabilities during periods of high diagnostic demand. For example, most data integrations were conducted via synchronous REST API to ensure data consistency and facilitate smoother integration with existing systems and middleware components, leading to the following issues:
- Blocking I/O Operations: In synchronous operations, I/O operations would block the execution until completion. This would result in inefficient use of computer resources, as threads would be occupied waiting for I/O operations to complete rather than being used to handle other requests.
- Tight Coupling: Synchronous REST APIs require both the client and server to be available and responsive simultaneously. This tight coupling leads to dependencies that complicate deployments and scaling, as both systems must be online and in a good state to communicate. Any downtime or performance issues in one system can directly affect the other.
- Latency Sensitivity: The synchronous nature of the REST APIs means that the client waits for the server to respond before proceeding. Significant latency is introduced if the server takes time to process the request. This waiting period can degrade user experience or delay processing in time-sensitive applications.
- Resource Inefficiency: Holding resources while waiting for a response is inefficient. For example, web servers hold onto HTTP connections and other resources during the request. This leads to resource exhaustion, especially under high load, potentially leading to slower response times or service outages.
- Error Handling Complexity: Error handling is more complex in synchronous data integrations because the client must manage retries, handle timeouts, and cope with other error conditions in real-time. This increases the complexity of the code and makes it harder to maintain.
- Scalability Issues: Scaling synchronous systems is challenging. As demand increases, both the client and server need to scale accordingly. However, synchronous calls become a bottleneck when the server needs to handle multiple lengthy requests simultaneously.
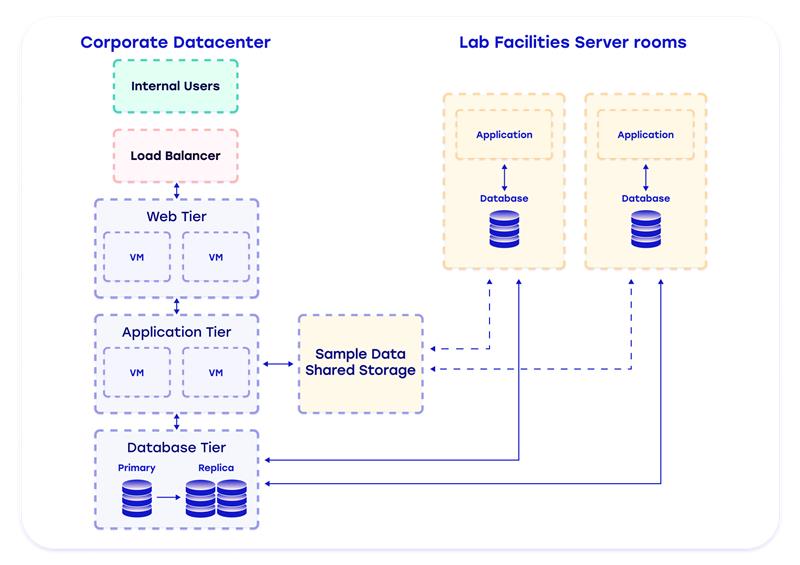
Compliance and Security Challenges
The inflexible structure of the data center networking and the absence of an advanced role-based Identity and Access Management (IAM) permissions model have made implementing modern compliance and security regulations such as GDPR, ISO 27001, and SOC2 more complex. This lack of flexibility and specificity in access controls significantly hindered the organization’s ability to enforce security policies and ensure compliance effectively. As regulatory demands evolve, the existing infrastructure’s limitations jeopardize data security and complicate compliance efforts, potentially leading to legal and financial repercussions.
By migrating to the cloud, the company can alleviate the burdens of its outdated infrastructure and take advantage of the benefits of an advanced cloud environment.
Solution Overview
AWS Cloud was chosen because it offers significant advantages to enterprise customers, particularly in security compliance and enterprise-grade support. The platform offers advanced security features that meet rigorous compliance standards required in many industries, including GDPR, ISO 27001, SOC2, and more. This compliance capability is supported by comprehensive tools that automate security tasks like identity management (IAM) and threat analysis (AWS Security Hub, Amazon GuardDuty, Amazon Macie), ensuring that businesses can effortlessly maintain a strong security posture. AWS was chosen for its unique combination of robust AI-enabled security services designed to identify sensitive data types such as personally identifiable information (PII) and help discover and protect sensitive data. These services use machine learning to automatically discover, classify, and protect sensitive data in AWS S3.
As the company moved away from old systems, it worked with a Helmes development team and the Client product team to shift Java applications to a cloud-based runtime platform. It adopted technologies such as AWS EKS, Docker, Helm, Terraform and modern approaches to Infrastructure such as Code (IaC) and CI/CD processes. This change allows the systems to adjust resources dynamically to meet demand, ensuring optimal performance even during peak usage periods. This improved scalability and elasticity bring new life into its once-static legacy systems.
In previous on-premises infrastructure, each resource was fixed, leading to high maintenance costs, dedicated teams for upkeep, and downtimes due to hardware failures. The company has streamlined cost management into a more efficient model by shifting to a cloud-based infrastructure. The pay-as-you-go approach ensures that it only incurs costs for the resources it actively uses, eliminating the inefficiency of resource over-provisioning. This cost optimization strategy not only reshapes our budgeting horizon but also ensures a more strategic allocation of resources, enhancing overall operational efficiency.
The company expected this transition to result in substantial cost savings and enable it to capitalize on exclusive offers from AWS partners, which align with its business objectives. In addition, the engineering team had extensive expertise and hands-on experience with AWS services and architecture. This familiarity ensured a smoother transition, minimized potential risks, and allowed it to fully leverage AWS’s scalability, security, and innovative cloud solutions for optimized performance and future growth.
AWS offers enterprise-grade support levels critical for businesses that rely on their cloud infrastructure for mission-critical operations. This support includes 24/7 access to Cloud Support Engineers, guidance from technical account managers, and proactive programmatic support to help enterprises optimize performance, reduce costs, and innovate more quickly. These features make AWS Clous an optimal choice for projects seeking a secure, compliant, and robust cloud computing solution.
Solution Diagrams
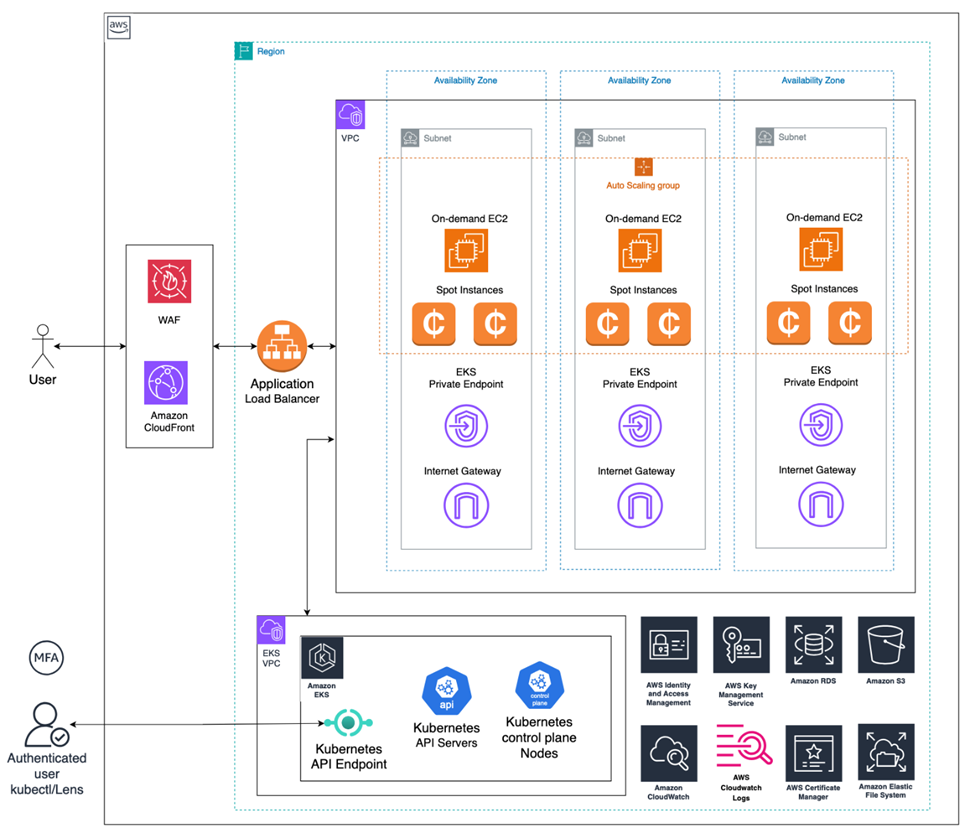
CI/CD Baseline Architecture
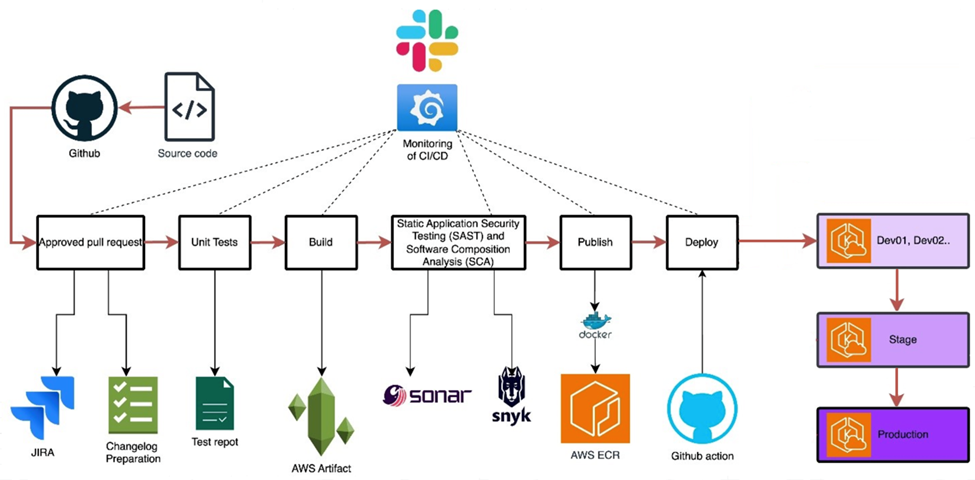
Detailed Description
Embracing Modularization and Microservice Architecture
We proposed transitioning from monolithic Java applications to a microservice architecture to overcome scalability limitations. This involves using AWS Cloud services to ensure scalability, flexibility, and improved system resilience. This architectural shift aims to break down the large, rigid monolithic system into smaller, independently scalable services, each running its own process and communicating via HTTP API.
To support this new microservice architecture, we made use of several AWS services that enhance the performance, scalability, and maintainability of the application: AWS Elastic Kubernetes Service (EKS) + AWS Spot Instances, AWS Application Load Balancer (ALB), Karpenter Autoscaler, Amazon ECR, Amazon key management system, CloudWatch Metrics and Alarms.
Providing a Secure and Highly Available Microservices Deployment Strategy
To create a robust, secure, and highly available deployment solution for a microservice architecture utilizing AWS Elastic Kubernetes Service (EKS), the following comprehensive strategy outlines the use of multiple AWS services to ensure encryption of data at rest and in transit, secure management of secrets, multi-AZ deployment, and effective monitoring and availability enhancements.
Encryption at Rest is achieved by integrating AWS Key Management Service (KMS) with EKS, which provides envelope encryption for Kubernetes secrets. Data stored in etcd.io, the key-value store used by Kubernetes, is encrypted, ensuring sensitive application secrets and configuration data are protected.
Encryption in Transit secures data flows between EKS nodes, enforcing mutual TLS (mTLS) via Istio to protect communications between microservices.
For secure secrets management, AWS KMS is used to encrypt API keys, database credentials, and other sensitive information, while AWS IAM Roles for Service Accounts (IRSA) allows controlled access to AWS resources without exposing sensitive credentials within the EKS cluster.
Ensuring High Availability and Resilience in AWS EKS Deployments
To achieve high availability and resilience in AWS Elastic Kubernetes Service (EKS) deployments, we implemented several critical strategies. We deployed Multi-AZ EKS Nodes across multiple availability zones within an AWS region to ensure that applications remain operational even if one zone experiences a failure. This significantly improves overall system stability and fault tolerance for microservices.
Additionally, we used AWS Spread Placement Groups to further enhance resilience by placing EKS worker nodes on distinct underlying hardware. This reduces the risk of correlated failures that could impact multiple nodes simultaneously.
The AWS Application Load Balancer (ALB) is used for traffic management. It distributes incoming requests across availability zones, which improves fault tolerance. The ALB also performs health checks to ensure that traffic is only routed to healthy instances. In addition, AWS Route 53 Health Checks and routing capabilities provide intelligent DNS management, directing traffic based on health status, latency, and geographic location, ensuring optimal performance and availability, even across multiple regions. This comprehensive approach maximizes uptime and service reliability for microservices running on AWS EKS.
Monitoring and Alerting
Effective monitoring and alerting are essential for maintaining performance and swiftly responding to issues in AWS EKS environments. Amazon CloudWatch Metrics and Alarms provide real-time visibility into EKS clusters and associated AWS resources. By setting up alarms, teams can proactively manage incidents and optimize performance based on predefined thresholds.
To enhance observability, CloudWatch Container Insights offers detailed monitoring of containerized applications, visualizing key metrics like CPU, memory, disk, and network usage. Automated dashboards help diagnose performance issues and failures, enabling rapid response to inefficiencies within microservices.
Additionally, integrating AWS X-Ray provides end-to-end tracing of requests through the microservices architecture, helping to identify bottlenecks and improve overall system performance. This comprehensive monitoring strategy ensures robust visibility, allowing for proactive management and optimized operation of EKS deployments.
Retaining Oracle Databases: A Strategic Decision
The decision to stick with Oracle databases rather than migrating to PostgreSQL is mainly based on security and operational considerations. Oracle offers advanced security features like comprehensive encryption, fine-grained auditing, and data masking, which are crucial for protecting sensitive data and ensuring regulatory compliance. AWS offers robust support for Oracle through Amazon RDS, offering automated backups, patch management, and scalability, enabling us to take advantage of Oracle’s security and performance within a managed cloud environment.
Migrating from Oracle to PostgreSQL would come with substantial costs. These include not only the technical hurdles of migrating data and integrating systems, but also potential disruptions to business operations during the transition. The expenses associated with migration, including both time and resources, may outweigh the benefits of switching to a free database.
Optimizing CI/CD with Amazon EKS and Spot Instances
We implemented Amazon Elastic Kubernetes Service (EKS) on Spot Instances to power the CI/CD pipelines. Our goal is to strike a balance between cost efficiency, scalability, and resilience. This decision capitalizes on EKS’s fully managed Kubernetes service, which automates essential tasks, allowing the team to concentrate on delivering high-quality software.
Using Spot Instances significantly reduces infrastructure costs by tapping into AWS’s unused computing capacity at a fraction of the usual expense. This makes high-volume CI/CD workloads more affordable.
EKS dynamically scales to meet the demands of CI/CD processes, ensuring consistent performance during peak times without manual adjustments.
We used Docker containers to run GitHub Actions self-hosted runners, which provide isolated environments. This enhances security by preventing cross-contamination between jobs.
Self-hosted runners offer tailored environments that optimize CI/CD workflows, resulting in faster job execution and the capability to run more concurrent jobs.
The integration of Docker, GitHub Actions, and EKS streamlines the deployment process from code commit to production, reducing manual intervention and minimizing errors.
This setup not only reduces operational costs but also enhances the efficiency, security, and reliability of our CI/CD pipelines, enabling faster and more confident feature delivery.
Advanced security solution
Several AWS security services are employed to ensure the security of the infrastructure and compliance with ISO 27001 and SOC2 standards. Each service addresses specific security threats and provides a robust security posture for the healthcare diagnostics platform.
Identity and Access Management
Identity and Access Management (IAM) is used to manage and secure access to AWS resources. It helps prevent unauthorized access and insider threats by implementing the principle of least privilege. By defining specific permissions, we ensure that users and applications have only the necessary access needed to perform their tasks. Multi-Factor Authentication (MFA) provides an extra layer of security, guarding against unauthorized access even if credentials are compromised. IAM roles can be assigned to services like EC2 and Lambda, enabling them to securely interact with other AWS services without including credentials in the application code.
Threats Addressed by IAM
Unauthorized Access: IAM policies enforce least privilege access, ensuring only authorized users can access sensitive resources.
Credential Compromise: The risk associated with compromised credentials is reduced using MFA and rotating IAM access keys.
Insider Threats: CloudTrail’s detailed logging and monitoring of IAM activities enable the detection and response to suspicious activities by insiders.
Web Application Firewall
AWS WAF protects web applications by filtering and monitoring HTTP and HTTPS requests. It helps prevent threats like SQL injection, cross-site scripting (XSS), and DDoS attacks. With custom rules, AWS WAF can block malicious traffic and protect against common web exploits. Integration with AWS Shield offers added protection against more significant DDoS attacks, ensuring the application remains available even during an attack.
AWS Security Hub
AWS Security Hub provides a comprehensive view of the security state of AWS resources by aggregating findings from various AWS services. It continuously monitors the environment against security standards and best practices to identify compliance gaps and vulnerabilities. By consolidating security alerts into a single dashboard, Security Hub enables quick identification and remediation of potential threats.
Specific Threats Addressed by Security Hub
- Configuration Vulnerabilities: Security Hub identifies misconfigurations that could lead to security breaches by evaluating AWS resources against best practices and compliance standards.
- Compliance Gaps: Continuous monitoring against ISO 27001, SOC2, and other frameworks ensures ongoing compliance.
- Unresolved Security Issues: Security Hub aggregates findings from services like GuardDuty, Inspector, and Macie to help prioritize and address critical security issues promptly.
Amazon GuardDuty
Amazon GuardDuty is a threat detection service that continuously monitors AWS accounts and workloads for malicious activity and unauthorized behavior. It uses machine learning, anomaly detection, and integrated threat intelligence to identify threats such as compromised instances, malicious IP addresses, and unusual account activity. GuardDuty findings are actionable and can trigger automated responses to mitigate threats.
Specific Threats Addressed by GuardDuty include
- Compromised Instances: It detects unusual behavior in EC2 instances and EKS Kubernetes containers that may indicate a security compromise, such as connections to known malicious IP addresses.
- Unauthorized Access: Identifies attempts to access resources from unusual locations or through unusual patterns, suggesting potential credential compromise.
- Data Exfiltration: Monitors S3 bucket activities to detect large data transfers or access patterns indicative of data theft.
Results and Benefits
The laboratory conducting clinical trials achieved significant improvements in security, scalability, and compliance by migrating its IT infrastructure to a modern cloud environment. This transition allowed the lab to maintain high data protection standards and adhere to stringent regulations such as ISO 27001 and SOC2.
The cloud infrastructure provided several specific benefits to this project:
- Enhanced Data Security: It ensured the protection of sensitive patients and trial data through robust security measures, reducing the risk of data breaches.
- Improved Scalability: It enabled the lab to quickly scale its operations to handle increased data volumes and user demands, supporting a 30% increase in trial participants without increasing the time of each trial.
- Cost Efficiency: It reduced the total cost of ownership of IT infrastructure by 28%, allowing more budget allocation towards core research and development activities.
- Compliance and Regulatory Adherence: It facilitated seamless compliance with industry standards and regulatory requirements, ensuring all clinical trials meet the necessary legal and ethical guidelines.
These benefits collectively contributed to more efficient and secure clinical trials, ultimately accelerating the development of new medical treatments and improving patient outcomes.
Get in touch



