

Executive summary
In 2024, Helmes partnered with an international financial institution to automate their PCAF-aligned GHG emissions reporting process. Within ten months, our team built a cloud-native, Azure Databricks–based solution that integrates with Snowflake, Azure Data Lake Storage, Streamlit, and Soda.
The client gained a seamless workflow – automated end-to-end, and integrated with the organization’s IT infrastructure.
A similar solution can support companies subject to the EU’s Corporate Sustainability Reporting Directive by improving data quality, automating data flows, and simplifying compliance with reporting requirements.
The challenge
Our client, an international financial institution, wanted a solution that would automate the measuring and reporting of the GHG emissions of their portfolios and to be able to use it already in 2025. The client has been committed to reporting its financed emissions according to the PCAF standard since 2022.
The Partnership for Carbon Accounting Financials (PCAF) provides financial institutions with a standardized method for measuring and reporting greenhouse gas emissions from their loans and investments. As the EU’s new Corporate Sustainability Reporting Directive (CSRD) expands mandatory annual sustainability reporting starting from 2025, and regulators recommend considering PCAF for reporting financed emissions, the framework is becoming the de facto standard in the EU for this part of sustainability reporting.
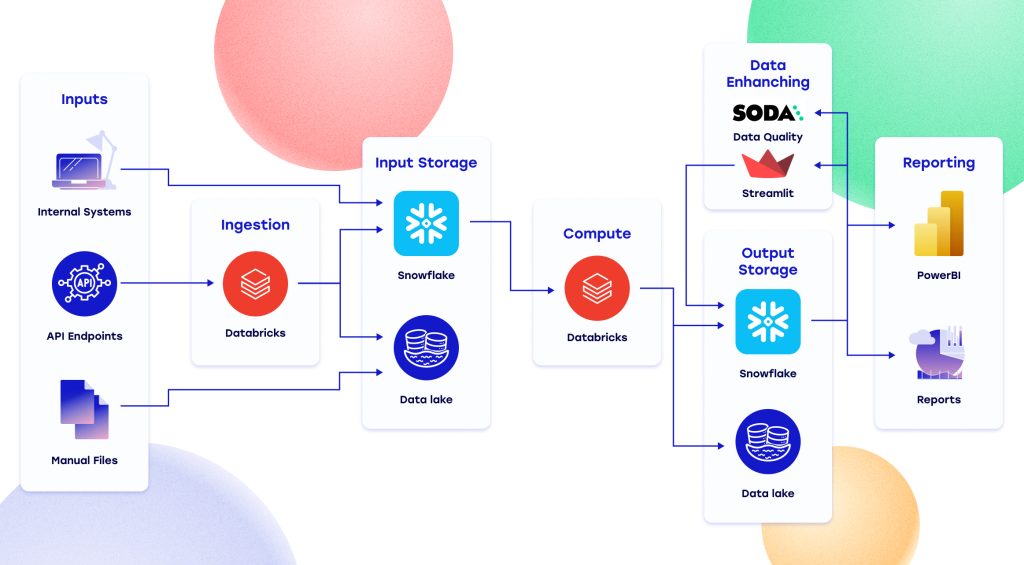
The solution
Before enlisting our help, the client had already successfully implemented a Python-based proof-of-concept that relied on manual data uploads and ran the required calculations on a single dedicated computer. The client was already using Azure Databricks, Azure Data Lake Storage, Snowflake, Streamlit, and Soda within its other IT architecture, and wanted to stick with them. Our task was to integrate all the tools into one seamless workflow.
In under a year, we turned their proof-of-concept into a scalable, automated solution built on Azure Databricks. The system runs scheduled Python and Spark workflows that ingest data from multiple sources via secure APIs, apply PCAF-compliant calculations, and publish results to Azure Data Lake and Snowflake for easy access and analysis.
We optimized API performance by 55%, and the next steps will include adding continuous data-quality monitoring with Soda, and building a Streamlit app for commenting and verifying data. Each tool plays a clear role:
- Databricks handles orchestration and compute;
- ADLS is the landing and historical store;
- Snowflake provides SQL-ready access for the team;
- Streamlit offers a simple UI for commenting data;
- Soda ensures data-quality checks.
The outcome is a robust, low-maintenance automation framework that streamlines carbon-footprint reporting and supports future business and regulatory changes with minimal effort.
While similar functionality could have been achieved with fewer components, combining the strengths of each tool maximizes usability for different user groups.
Results & benefits
55% faster API-calls: optimizing data calls reducing computing costs and times.
Fast reporting: automating manual processes accelerates reporting significantly.
Lower workload: the team spends now only a fraction of the time on data handling
Eliminating errors: automated dataflow and data quality monitoring via alerts and dashboards (scheduled for development)
Easily accessible data: all source and output data are readily available to all business units
Data-based decisions: Power BI visualization and insights support the team in decision making
Security: role-based security ensures that data is only accessible to authorized team members.
Future possibilities include building AI-based features, for instance, for finding data currently not available via APIs – a challenge we’re happy to take on. And if you’d like to enquire what our data experts could do for your organization, don’t hesitate to book a consultation (it’s free).
Helmes’ team felt like an extension of our own team. They approached the project with care and a clear understanding of the direction we want to take.
The Client
Co-operation and project management
The project was completed in under a year and is now in maintenance status, requiring no significant developments as long as the reporting standards remain unchanged.
This was made possible thanks to the high level of co-operation and general supportive attitude our Client brought to the project. Throughout the process, we worked closely with their IT and business teams. Together, we defined the business needs, selected the tech stack and devised the architecture of the future solution.
Although the client has an in-house IT team, they recognized that enlisting external data expertise and bringing in experienced Azure- and Databricks-certified specialists would significantly enhance their ability to deliver the best solution for their needs within a limited timeframe. According to our Client, Helmes – with our team of 60+ Data and BI experts and renown work ethic – was an easy pick for the role.
We helped build a scalable, trustworthy solution for PCAF reporting, automating the process from end-to-end – from ingesting and verifying data from multiple source systems to running automated calculations and making the results available across the organization.
The process
The process evolved step by step, combining technical modernization with close collaboration to ensure the solution met both PCAF requirements and the client’s practical business needs.
Migrating the on-premises Python project into scheduled Databricks notebooks
Together with the client, we turned the proof-of-concept into a scalable automated solution that uses Azure Databricks as its backbone.
Databricks is a powerful data platform that lets both business users and data engineers build what they need using Python and Spark notebooks. Work is organized into small code blocks you can run all at once or individually and see the output immediately. That makes it easy for analysts, ML engineers, and data scientists to develop modular Python workflows that can be turned into automated processes.
The platform runs the scheduled calculations and publishes results to both the client’s data lake (for storage and easy reruns) and Snowflake database (where it is easily accessible for business users through SQL queries).
(With granular data originating from multiple operational source systems, it is always a good idea to centralize them in a data lake/data warehouse (depending on the needs). The data lake structures and stores all incoming data, allowing past calculations to be easily replicated if needed.)
Developing the process to incorporate integration of PCAF standard and business needs
We refined the existing proof-of-concept to meet the evolving business needs and continued to support client in PCAF GHG Accounting and Reporting.
Changing inputs from manual files into API calls and database queries
The solution automatically ingests data from internal and external systems, including PCAF’s databases, via secure APIs, almost eliminating the need for manual uploads. The team now needs to manually upload only minimal data for which automation is not possible, which has considerably reduced their workload and sped up the process.
Optimizing API calls to run up to 55% faster
In addition to automating data ingestion, we further sped up the process by optimizing data calls.
Implementing data quality checks (upcoming in 2026)
The system uses Soda to continuously monitor data and verify it for potential issues requiring attention. For instance, it sends out alerts when incoming data is missing or incomplete, or there are unusual deviations in calculation results (for example, resulting values are too low or too high).
Creating a Streamlit app to comment on data (upcoming in 2026)
One of the business requirements was adding the possibility to comment on the data as needed. For instance, users might want to highlight any issues with the data or note that its accuracy has been verified.
We will implement this feature as a Streamlit app linked to the Snowflake database. The users will be able to add comments in a Streamlit app, made visible to other users in the Snowflake database.
Making outputs available to the team through a Snowflake database and BI solutions
Snowflake gives authorized users across the organization convenient access to the data. Team members from different business units can easily perform SQL queries and use the data for reporting and decision-making.
The Snowflake database is connected to Power BI for additional visualization and insights.
As a result, the team can easily track the GHG emissions of portfolio companies and any significant changes in their carbon footprint.
Work with us
With 30+ years of custom development expertise, including telecom, banking, retail, healthcare and government, Helmes is your trusted partner in digital transformation.
We have the largest data and AI team in the Baltic countries, with over 60 specialists ready to provide specialized BI, data analytics and data science expertise for projects or build complex data solutions from scratch.
If you’re seeking an experienced partner to automate sustainability reporting or solve other data challenges, we’d like to hear from you.
Get in touch
